Tutorial¶
The following tutorial comes in the form of a Jupyter notebook. The notebook can be downloaded here.

IRISreader Tutorial Notebook¶

This notebook explores the functionality of IRISreader.
If you have not installed IRISreader yet, please follow the installation guide in the README. IRISreader relies heavily on numpy. If you are not yet familiar with numpy, please read the following quickstart tutorial. To install Jupyter to access the notebook, please read their installation instructions. If you have any comments, feel free to drop me a note.
In the notebook we will use the following libraries in addition to IRISreader:
import matplotlib.pyplot as plt
import numpy as np
Part 1: Configuration¶
Let us first make sure that irisreader is properly configured:
import irisreader as ir
ir.config
We keep verbosity_level = 1 for interactive mode. If you are inside the FHNW network, comment out the next command and change the default data mirror to 'fhnw' (makes things much faster). Otherwise just leave it and download from LMSAL. If you already have some downloaded data on your harddrive, feel free to omit the download step and replace the observation directory path in obs = observation( .. ).
#ir.config.default_mirror="fhnw"
Part 2: Data Access¶
# Note: In this notebook we will download some data, if you prefer to work in another directory than the current one,
# please change the path:
import os
os.chdir( "." )
from irisreader.utils import download
download( "20140910_112825_3860259453", target_directory="." )
The download function would have actually already opened the observation for you. Let us however do this on our own for educational purposes this time:
from irisreader import observation
obs = observation( "20140910_112825_3860259453" )
Let us check the different attributes of this observation. The most basic information can be found by simply printing out the observation object:
print( obs )
Here are a few more attributes:
obs.obsid
obs.mode
[obs.start_date, obs.end_date]
The SJI and raster data cubes can be accessed through the sji and raster loaders:
SJI:¶
obs.sji.get_lines()
obs.n_sji
The individual SJI lines can be accessed either by accessing the loader with an index or by calling the loader with a search string that uniquely identifies the line:
obs.sji[0].line_info
obs.sji[1].line_info
obs.sji("Si").line_info
obs.sji("Mg II h/k").line_info
Notice the warning. Here there are in general two different type of Magnesium windows (the other one is the Mg II wing). The search string is clear in this case, but it will not be if you search through a large corpus of observations.
Raster:¶
obs.n_raster
There is only 1 raster file present. For n-step rasters, where the camera sweeps $n$ times over the same region, there will be $n$ files in the observation. As we will see below, IRISreader abstracts all the individual raster files as one.
obs.raster.get_lines()
Similar to the SJI, the raster lines can be access through an index and a search string interface:
obs.raster("Mg II k").line_info
obs.raster[4].line_info
1.2: Data Cube and Header Access¶
Data cubes and headers can be accessed through the loaders sji and raster. IRISreader uses a lazy loading approach, loading data and headers only once they are requested.
Headers¶
Let us start with header access. Each line contains the data cube stored in the FITS extension and primary and time-specific (and for rasters even line-specific headers). All the headers belonging to a line can be simply accessed with headers[<time step>][<header key>]. If you want to access only the primary headers, time-specific headers or line-specific headers, you can access them through primary_headers[<header key>], time_specific_headers[<time step>] and line_specific_headers[<header key>] respectively.
Notice how it takes longer to access the header the first time, because IRIS loads the headers only upon your first request:
%time obs.sji("Si").headers[0]['SAT_ROT']
%time obs.sji("Si").headers[0]['DATE_OBS']
obs.sji("Si").primary_headers['HISTORY']
obs.sji("Si").time_specific_headers[10]['XCENIX']
obs.raster("Mg II k").headers[0]['ENDOBS']
obs.raster("Mg II k").line_specific_headers['WAVENAME']
(similarly, primary_headers and time_specific_headers can be accessed for rasters)
Data¶
IRISreader uses astropy.fits to open FITS files, which relies on memory mapping, i.e. files are read directly from the hard drive instead of loading them into RAM. Of course as soon as the data is processed, it has to be loaded into memory.
Data access can be done in two different ways, depending on the access type:
1. Time slices (images)
Most of the time, one will want to access single images at a time and perform some computations on them. Then it's most efficient to load the images into memory only upon request. This can be done with the get_image_step functionality:
obs.sji("Si").get_image_step(10)
We can plot this image with matplotlib:
plt.imshow( obs.sji("Si").get_image_step(10).clip(min=0)**0.4, origin="lower", cmap="gist_heat", vmax=10 )
plt.show()

Here we applied a gamma correction of 0.4 to make the image look nice and cut it off at a good intensity. Also, we set all negative pixel values to zero with clip. The plot function can do this directly: (note that we can control the size of the figure in the notebook with plt.figure(figsize=(x,y)))
plt.figure( figsize=(10,10))
obs.sji("Si").plot( 10, units="coordinates", cutoff_percentile=99 )

where we used coordinates on the Sun instead of CCD pixels. This function automatically applies a gamma correction of 0.4, you can manually set it through the argument gamma.
2. Arbitrary slices
If the user desires a specific slice of the data, it is often more efficient if the data is loaded into memory first. The slices can then be accessed through an index. We show this for a raster, but the access is similar for SJI. The slice access follows the format [ time step, y pixel, wavelength pixel ], where the wavelength pixel number can be replaced with the x pixel number for SJI. Notice the convention here that $y$ comes before $x$.
In the following we want to create a two-dimensional plot that shows the evolution of a fixed wavelength along the y-axis over time:
mg_slice = obs.raster("Mg II k")[:,:,100].clip(min=0)
mg_slice.shape
plt.figure( figsize=(10,5) )
plt.xlabel( "time step" )
plt.ylabel( "y on slit" )
plt.imshow( np.transpose(mg_slice)**0.4, cmap="gist_heat", vmax=10 )
plt.show()

This looks already nice! We used a gamma correction of 0.4 to see more structure in the image. However notice the dark region at the right end. Because a flare occured there, IRIS had to reducethe exposure time. Thus the previous 'quiet' part of the image looks now much darker. We can get rid of this by dividing through exposure time:
exposures = [h['EXPTIME'] for h in obs.raster("Mg II k").headers]
plt.figure( figsize=(10,5) )
plt.xlabel( "time step" )
plt.ylabel( "y on slit" )
plt.imshow( (np.transpose(mg_slice) / exposures)**0.4, cmap="gist_heat", vmax=4.5 )
plt.show()

This concludes the data access part. Let us close the observation and all open file handles that are tied to it:
obs.close()
Part 2: Basic Preprocessing¶
IRISreader offers some basic preprocessing functionalities that help making the data ready for machine learning tasks. In the following, we will look at image cropping and spectrum interpolation:
2.1 Image Cropping¶
Did you notice the black borders in the images above? They are here because in IRIS level 1 data there is some misalignment in the CCD images; to correct for this misalignment, the images are rotated into the right position during level 2 processing. However, this rotation leaves some artefacts in the form of regions where all pixels are set to -200 (which we call NULL here) which the plot function displays as black. Notice that also black regions due to dust particles on the camera have negative pixel values.
IRISreader comes with a cropping algorithm, that makes a choice in cropping out the non-negative part of the image. While an astronomer will probably prefer to keep as much information in the image as possible, for big data processing tasks we rather lose some data but are then sure that the data comes in a good format without artefacts. The IRISreader cropping algorithm works by sending a line from each frame border towards the image center, counting the number of non-negative pixels along the line. Once the number of non-negative pixels stops increasing, it stops moving the line towards the center. Once this is done for all four sides, we have defined a frame that contains no negative pixels (or at least only a few from dust and some other image corruptions - images with more than 5% negative pixels after cropping are automatically discarded as being corrupt by the algorithm). Here is a sketch of how the cropping algorithm works:
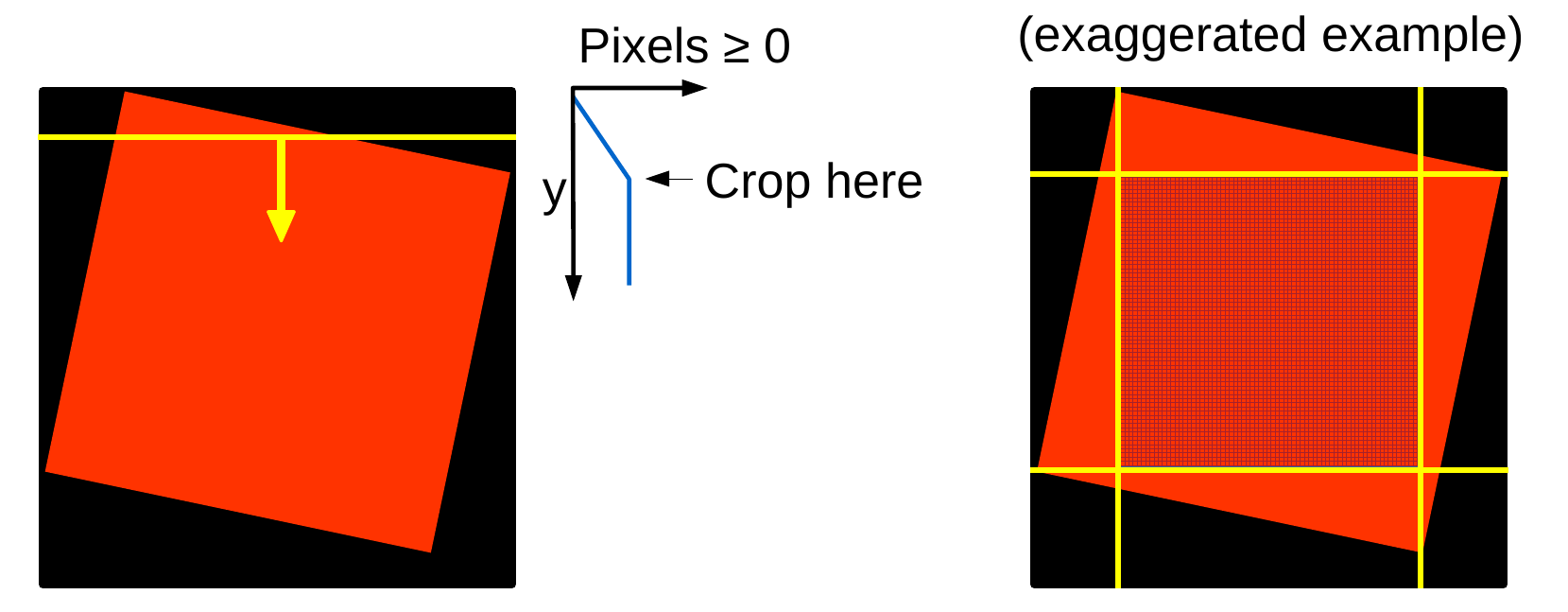
You can find the implementation of the algorithm in irisreader.preprocessing.image_cropper and an application of this algorithm to image cubes (finds the best boundary for all images in a cube) in irisreader.preprocessing.image_cube_cropper. However, you do not need to take care of this classes, everything is already done for you in the crop method of the sji and raster classes:
obs = observation( "20140910_112825_3860259453" )
plt.figure( figsize=(10,10))
obs.sji("Si").plot( 0, cutoff_percentile=99 )

obs.sji("Si").crop()
Notice that you can avoid the progress bar via ir.config.verbosity_level=0
Let us now plot the first image of the cropped data cube:
plt.figure( figsize=(10,10))
obs.sji("Si").plot(0, cutoff_percentile=99)

This looks nice! Only a few pixels on the sides are lost. In general, this algorithm works very well. We can also do this for a raster:
obs.raster("Mg II k").crop()
plt.figure( figsize=(10,10))
obs.raster("Mg II k").plot( 0 )

There is also an option in the plot function to plot only one spectrum on a pixel of the y-axis:
obs.raster("Mg II k").plot( 0, y=350 )

2.2 Spectrum interpolation¶
Say we want to read spectra from many different observations and perform a machine learning task on this data. The spectra come in many different resolutions (as the data downlink is limited and expensive, sometimes more line windows with a worse resolution are preferred over only a few line windows with a good resolution).
IRISreader has a function ready that interpolates all the spectra to a common interval, look at the following example:
lambda_min = 2794
lambda_max = 2800
n_breaks = 100
interpolated_image = obs.raster("Mg II k").get_interpolated_image_step( 0, lambda_min, lambda_max, n_breaks=100 )
plt.xlabel( r'Wavelength [$\AA$]' )
plt.ylabel( "Data number" )
plt.plot( np.linspace( lambda_min, lambda_max, n_breaks ), interpolated_image[400] )
plt.show()

The algorithm has cut out only the region between $\lambda_\text{min} = 2794 \, Å$ and $\lambda_\text{min} = 2800 \, Å$ and has interpolated the spectrum to 100 steps.
Part 3: Browsing Observations¶
Iterating through large sets of observations is a very basic need if one wants to treat IRIS data as a big data problem. In the following you will learn how to do this in a very simple way with the obs_iterator class. Unfortunately, you might not have a larger corpus of observations available. If you want to download a few ones with flares in it, use the code below to download them (will probably take 1-2 hours). Otherwise feel free to just read through the next part and acknowledge the possibilities that you have with obs_iterator.
download( "20140329_140938_3860258481", target_directory=".", open_obs=False )
download( "20140331_024530_3860613353", target_directory=".", open_obs=False )
download( "20140906_112339_3820259253", target_directory=".", open_obs=False )
download( "20140418_123338_3820259153", target_directory=".", open_obs=False )
Now let us create an iterator and print out the description of each observation:
from irisreader import obs_iterator
for obs in obs_iterator("."):
print( '{}: {}'.format( obs.obsid, obs.desc) )
This is easy! obs_iterator finds all directories that are IRIS observations and makes them iterable. We can also plot the first image of each Si IV slit-jaw image as a quicklook:
for obs in obs_iterator("."):
if obs.sji.has_line("Si IV"):
obs.sji("Si IV").plot(0)
plt.show()




Part 4: GOES X-ray Flux and HEK Coalignment¶
IRISreader can download GOES15 XRS files and make them available for the observation class. Let us open our first observation once more:
obs = observation( "20140910_112825_3860259453" )
We can get a data frame with the associated GOES15 XRS data:
obs.goes.data
IRISreader will automatically download the necessary files and store them in the observation directory. GOES data is available under:
ir.config.goes_base_url
If you are inside the FHNW network it is faster and safer (the NOAA server will e.g. be down during US government shutdowns that seem to be very common and long nowadays...) to use
# Might not have the latest data ready
#ir.config.goes_base_url = "http://server1071.cs.technik.fhnw.ch/goes/xrs/"
It is also possible to plot the GOES X-ray flux around and during the observation:
obs.goes.plot()

obs.goes.plot( restrict_to_obstime=True )

There is obviously an X-Flare taking place during this observation! Let's hope the IRIS pointed to this flare.. To that end there is a function that interpolates GOES X-ray flux (1-8 Å) to the timestamps of the pictures IRIS took:
goes_flux = obs.sji("Mg II h/k").get_goes_flux()
plt.xlabel("time step")
plt.ylabel(r"GOES 15 1-8 $\AA$ X-ray Flux")
plt.semilogy( goes_flux )
plt.show()

This allows us to get the image where the GOES flux was highest:
plt.figure( figsize=(10,10))
obs.sji("Mg II h/k").plot( np.argmax( goes_flux ) )

It is also possible to access Heliophysics Events Knowledgebase events that took place around the time of the observation:
obs.hek.data
There were three flares! Let's filter them out and investigate them more closely:
flare_df = obs.hek.data[ obs.hek.data.event_type=='FL' ]
flare_df[['event_endtime','event_peaktime','event_starttime','fl_goescls','hpc_x', 'hpc_y']]
Are these our flares? hpc_x and hpc_y are the world coordinates on the sun given by HEK, let's check whether IRIS' field of view is in the same region. To this end we use the pix2coords function of sji_cube to get the coordinates of the field of view corners:
sji = obs.sji[0]
xmin, ymin = sji.pix2coords(pixel_coordinates=[0,0], step=0)
xmax, ymax = sji.pix2coords(pixel_coordinates=[sji.shape[1],sji.shape[0]], step=0)
print("xmin = {}, xmax = {}, ymin = {}, ymax = {}".format(xmin, xmax, ymin, ymax))
xmin $\leq$ hpc_x $\leq$ xmax and ymin $\leq$ hpc_y $\leq$ ymax for two of the three events. Please notice that as solar flares have a certain extension, a single HEK coordinate pair is not an accurate measure of the flare location.
Finally, let's close the observation:
obs.close()
Part 5: The tools behind the OBS interface¶
Now you have already seen a great deal of what you can do with the OBS interface. This chapter is some optional reading, going a bit deeper into how the OBS interface is built up.
The foundation of IRISreader is the iris_data_cube class. This class opens a FITS file with IRIS data and reads the headers and the data in the extensions:
from irisreader import iris_data_cube
fits_data = iris_data_cube("20140910_112825_3860259453/iris_l2_20140910_112825_3860259453_SJI_1400_t000.fits")
fits_data.get_image_step( 0 )
The iris_data_cube class tries to give as much functionality as possible without taking into account the particularities of SJIs and rasters. The sji_cube and raster_cube classes inherit from iris_data_cube and implement SJI and raster-specific functionality on top of it (so if you're not trying to hack something, you should never use iris_data_cube):
from irisreader import sji_cube
sji = sji_cube("20140910_112825_3860259453/iris_l2_20140910_112825_3860259453_SJI_1400_t000.fits")
sji.plot(0)
from irisreader import get_lines
get_lines("20140910_112825_3860259453/iris_l2_20140910_112825_3860259453_raster_t000_r00000.fits")
from irisreader import raster_cube
raster = raster_cube("20140910_112825_3860259453/iris_l2_20140910_112825_3860259453_raster_t000_r00000.fits", line="C II")
plt.figure( figsize=(2,10))
raster.plot(0)

This observation was easy, because it only contains one raster (sit-and-stare). Let us open an n-step raster observation. The following code will download one of the example in the obs_iterator code if the directory is not there yet:
download( "20140329_140938_3860258481", target_directory=".")
Let's look at the raster files in the observation directory:
raster_files = ["20140329_140938_3860258481/" + file for file in os.listdir( "20140329_140938_3860258481" ) if 'raster' in file]
raster_files
That's quite a lot! With our current approach we would have to open all 180 files and check them out manually. For your convenience, the engine running under the raster_cube 'hood' is already implemented in an abstract way such that it automatically creates an interface that abstracts all the raster files to a single one:
raster = raster_cube( raster_files )
raster.shape
raster.n_files
The raster_cube class abstracts the 180 raster files as one with 1380 images. Notice that 1380 is not divisible by 180: this is because some images are usually entirely null and sji_cube and raster_cube automatically discard them by default (otherwise set keep_null=True).
raster.plot( 1200 )

Luckily, we can avoid all these steps by using the OBS interface:
obs = observation("20140329_140938_3860258481")
plt.figure( figsize=(2,10))
obs.raster("C II").plot(1200)

That's it! I hope you had fun.